

OSM wordt al jaren maandelijks door 5 miljoen gebruikers gespeeld. Al deze spelers verwachten dat ze snel hun wedstrijd kunnen checken nadat de wedstrijdsimulaties hebben gelopen. Die simulaties moeten bovendien duizenden competities in fracties van seconden berekenen. Hoe is dat mogelijk?
Onlangs zag ik een interessante video van Mark Zuckerberg uit 2005. Hier legt hij uit welke technische uitdagingen Facebook in het prille begin moest overwinnen. Hij is open en geeft veel details weg. Het spaarzaam opgekomen publiek, nota bene Harvard studenten die Software Engineering volgen, is hier nauwelijks in geïnteresseerd. Ik wel. Want ik moest bij het kijken van de video terugdenken aan mijn eigen, veel bescheidenere ervaringen met OSM.
Het verhaal van de server onder de trap bij mijn ouders thuis in 2001 heb ik al vaak verteld. Maar hoe ging het daarna verder? Het was zeker geen gemakkelijke overgang van enkele tientallen naar miljoenen spelers.
De primaire focus was heel wat jaren niet om meer spelers te krijgen. Maar om te zorgen dat al die spelers het spel tegelijk konden spelen, zonder dat de servers onder de druk bezweken. Een technische uitdaging dus.
Van één naar meerdere servers
Een server is niets anders dan een computer die altijd aan staat. Met OSM begin ik in 2001 logischerwijs met één server. In 2003 wordt dit te krap. Een logische stap is dan om de database een aparte server te geven. Dit geeft de nodige lucht.
Er zijn echter al snel teveel spelers die OSM tegelijk willen spelen. Zeker rond de wedstrijdsimulaties vertragen de twee servers aanzienlijk. Ik moet iets doen om geen ledenstop in te hoeven voeren.
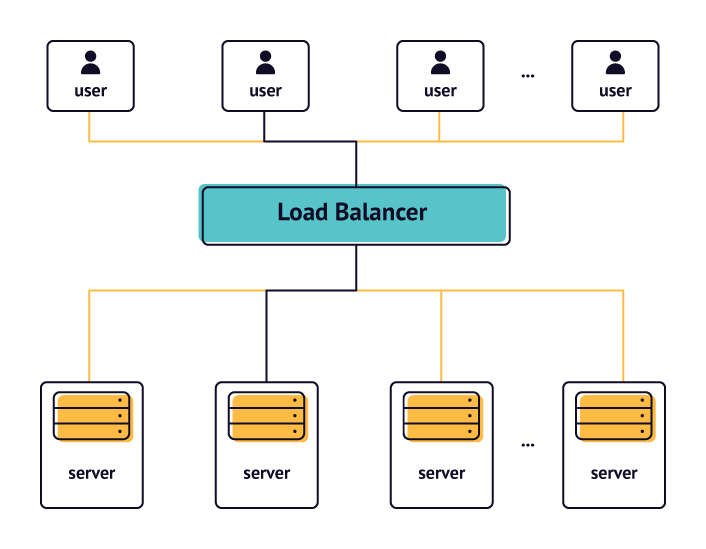
Load Balancing
Als volgende stap verdeel ik de website over meerdere servers. Dit doe ik met Load Balancing. Ik pas dit in eerste instantie in de primitiefste vorm toe, waarbij de twee applicatieservers de bezoekers over elkaar spreiden. Het aantal servers dat OSM draait, komt hiermee op drie.
Erg robuust is het niet. Als één van deze servers het begeeft, is de hele website down, wat regelmatig gebeurt en me heel wat slapeloze nachten bezorgt. Tot overmaat van ramp dient in 2004 een nieuwe bottleneck zich aan. De database. Die kan niet met Load Balancers werken. De data moet op een centraal punt worden weggeschreven. Het blijkt veel ingewikkelder om dat op te lossen.
De schaalbare database
De oplossing die ik kies, lijkt eenvoudig, maar is complex om door te voeren. Ik besluit de data te verdelen over verschillende servers, op basis van het competitienummer. De gebruikers houd ik centraal bij. De gegevens over de competities en de teams, worden over meerdere servers verdeeld.
Het kost me heel wat nachtelijke uren om dit te bouwen. Je moet je voorstellen dat de website op dat moment al kraakt in zijn voegen. Elke nacht kunnen de wedstrijden op het nippertje gesimuleerd worden. Het opvragen van je uitslag duurt steeds langer en de spelers worden ongeduldig. Het lijkt sterk op het verbouwen van een vliegtuig in volle vlucht.

Ik sta er op dat moment wat programmeren betreft alleen voor. Het lukt me uiteindelijk. Daar ben ik nog steeds trots op. Wat ik heb gedaan, met de beperkte kennis en middelen die tot mijn beschikking staan, heeft de groei van OSM tot miljoenen spelers mogelijk gemaakt.
Facebook heeft iets soortgelijks gedaan, door hun gebruikers over servers te partitioneren op basis van de scholen waar ze zich bevinden. In de beginfase van Facebook zijn het de universiteiten en andere scholen die de basis vormen van hun netwerk.
Nu ik de applicatie schaalbaar heb gemaakt, kan de groei meerdere jaren aanhouden. Miljoenen spelers spelen OSM. We voegen de ene na de andere server toe. Tot er tientallen servers staan te rekenen in het datacenter om alle wedstrijden elke dag te simuleren.
Grappig detail is dat we de servers voornamen geven van bekende voetballers. Zo hebben we Johan, Jaap, Diego, Lionel en Cristiano. We moeten wel creatiever worden met de namen naarmate er meer servers komen.







En nog meer schaalbaarheid
Behalve meer servers toevoegen, zie ik ook de hardware elk jaar beter worden. Ook de software blijkt steeds efficiënter te kunnen. Dat zorgt ervoor er steeds meer gedaan kan worden met minder servers.
Schaalbaarheid zit in het DNA van de organisatie. Ontwikkelaars trainen om hier altijd rekening mee te houden. Het is een mindset waar ik nog steeds profijt van heb. Zo geef ik in 2014 een gastcollege aan de VUA over schaalbaarheid. En in 2017 sta ik in de Dutch Innovation Factory met een talk over performance.
De queeste naar meer schaalbaarheid zorgt dat we dedicated redundante load balancers neerzetten. Dat we de kabels naar het datacentrum vergroten met meer capaciteit, omdat die anders vollopen. Dat we caching servers toevoegen zodat gegevens niet steeds uit de database gehaald hoeven te worden. We maken regelmatige snapshots, zodat data niet meer zomaar meer verloren kan gaan.
Toekomstige ontwikkelingen
De laatste jaren is schaalbaarheid minder urgent, omdat OSM niet zo hard meer groeit als in het begin. Desondanks heeft OSM een enorme schaal. Het blijft een aandachtspunt om ervoor te zorgen dat alles wat er gemaakt wordt in het spel niet alleen werkt voor enkele tientallen spelers, maar voor miljoenen gebruikers.
Er zijn veel interessante technologische ontwikkelingen de laatste jaren. Bijvoorbeeld op het gebied van cloud computing, container based deployments en event driven architecture. Deze en andere technieken dragen eraan bij dat onderhoud aan de infrastructuur waar OSM op draait makkelijker wordt.
Alles wordt beheerd door een team van doorgewinterde specialisten. Het draait allang niet meer dankzij één nerd op een zolderkamer.
Maar hoe het er achter de schermen ook aan toegaat, ik blijf het bijzonder vinden dat miljoenen mensen binnen een fractie van een seconde de prestaties van hun team kunnen opvragen.






 van zolderkamer tot skybox ligt nu in de winkels")


