

Van een technische speurtocht kan ik erg genieten, zeker als het me lukt om de oorzaak te vinden en het probleem op te lossen. In die zin ben ik nog steeds een echte nerd. Deze week viel het me op, dat ik al een tijdje geen e-mail van OSM had ontvangen. Normaal gesproken zou ik verwachten na drie dagen inactiviteit een e-mail te krijgen met de boodschap dat mijn team zich zorgen maakte. Zo zou dat ingesteld moeten staan. Maar het werkte duidelijk niet. Nieuwsgierig geworden naar de oorzaak, ging ik op onderzoek uit.
Met het gevaar dat het wat te technisch kan worden, zal ik proberen uit te leggen hoe deze zoektocht verliep.
Ik begon te kijken naar de mailer zelf. Dit leek me de meest logische plek waar het fout zou kunnen gaan. De statistieken van dit stukje software zijn inzichtelijk in ons back-end dashboard. Hier nam ik activiteit in waar. Op het eerste oog leek hier niets aan de hand. Maar bij nadere bestudering zag ik dat de cijfers onverklaarbaar afweken van wat ik verwachtte.
Segmentatie
Ik realiseerde me dat de gegevens voor het versturen van de e-mail verzameld worden in een taak die wij de ‘segmentatie’-taak noemen. Dit is een soort samenvatting van de gebruikersactiviteit, waar de mailer snel kan opzoeken wie welk mailtje moet ontvangen. Ik besloot deze segmentatietaak eens nader onder de loep te nemen.
Hier stuitte ik op iets zeer mysterieus. In de databasetabel waar de samenvatting van gebruikersactiviteit wordt bijgehouden, verwachtte ik honderdduizenden records te vinden. Ik zag er echter maar 987. En vreemder nog, terwijl de samenvatting werd bijgewerkt, veranderde er helemaal niets aan dit aantal. Dat kon ik niet verklaren.
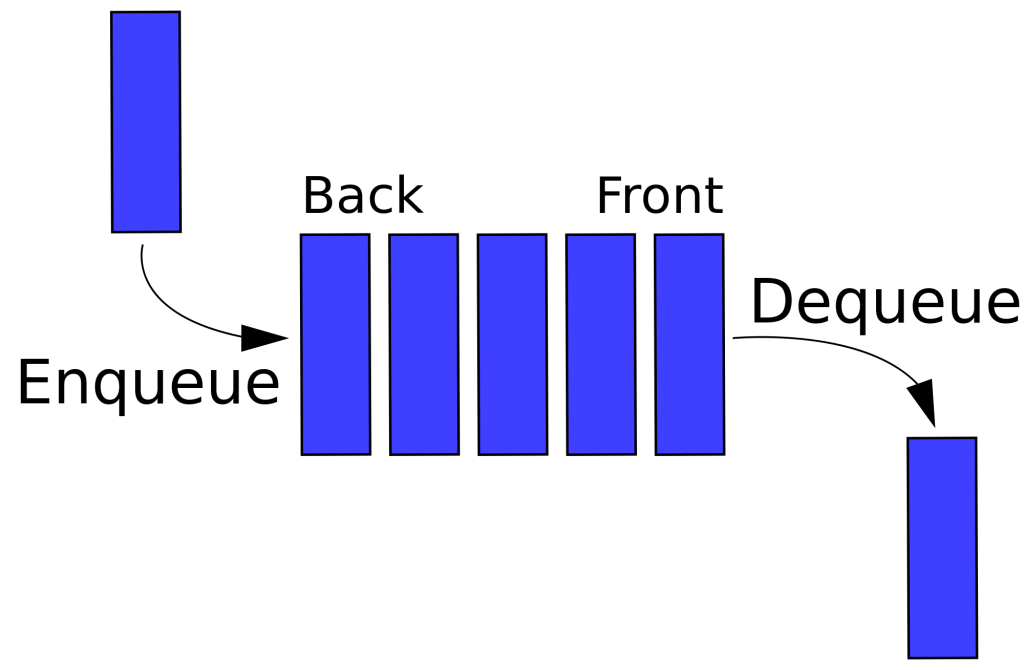
Om verder te komen, moest ik me gaan verdiepen in de manier waarop de segmentatietaak haar werd doet. Dit proces verwerkt de hele dag door de gebruikersactiviteit, maar leek dat nu niet meer te doen. Wederom was op het eerste gezicht alles in orde. De taak was actief en draaide. Wat echter bijzonder vreemd oogde, was dat de queue (rij) waar de data vandaan moest komen, enorm groot was.
In de rij
Een ware tsunami aan data, 161 miljoen bewerkingen, stonden te wachten om verwerkt te worden! En dat terwijl de taak er ogenschijnlijk elke seconde 1000 wegwerkte. Dat rijmde niet met elkaar.
Sinds eind november vorig jaar werden er geen items verwerkt. En dus ook, gelet op het oorspronkelijke probleem met de mailer, geen e-mail meer verstuurd.
Maar waarom? Het proces dat de segmentatie bijwerkte, draaide gewoon. Om erachter te komen wat er precies mis ging in de verwerking, haalde ik een collega van het developmentteam erbij. Met hem startte ik de taak op in ‘debug’-modus, dat wil zeggen dat elk stapje in de broncode kan worden bekeken en geanalyseerd.
We zagen dat elk item voorzien is van een uniek identificatienummer, waarmee bepaald wordt of deze verwerkt is. Dit ID stond bij verwerking op een bizar negatief getal, -2.147.483.648. In de databasetabel zag ik vrijwel hetzelfde getal, maar dan positief. Hoe was dat mogelijk?
2 miljard?
De verklaring bleek hem te zitten in een technische beperking van de programmatuur en hoe deze getallen opslaat. Een heel getal in de database kan, als er geen negatieve waarden hoeven te worden opgeslagen, minimaal de waarde 0 en maximaal de waarde 4.294.967.295 krijgen. Dit heet een UNSIGNED 32-BIT INTEGER. Wanneer er wel negatieve waarden ondersteund worden, halveert dit aantal, omdat ook de negatieve range eraan wordt toegevoegd. De minimale waarde wordt dan -2.147.483.648 en het maximum is 2.147.483.647.
De negatieve ID’s konden niet gevonden worden, waardoor het proces zichzelf herhaalde tot in het oneindige.
 Om 17:30 aan het einde van de werkdag, hadden we de oorzaak gevonden. Een onvervalst Eureka moment!
Om 17:30 aan het einde van de werkdag, hadden we de oorzaak gevonden. Een onvervalst Eureka moment!
Het equivalent van een paar honderd supercomputers uit de jaren ’80, heeft dag in dag uit staan stampen op nutteloze data.
More bits to the rescue
De oplossing voor dit probleem was gelukkig eenvoudig: het aanpassen van de ID naar een 64-bit integer. Hiermee kunnen tot 9.223.372.036.854.775.807 mogelijke waarden worden opgeslagen. Ruim voldoende om het tot het jaar 2100 of nog langer vol te houden.
Ik realiseerde me dat sinds 29 november, dus 50 dagen lang, onze servers ongeveer 2000 bewerkingen per seconde voor niets hadden uitgevoerd. Het equivalent van een paar honderd supercomputers uit de jaren ’80, heeft dag in dag uit staan stampen op nutteloze data. Het is een geluk dat deze computers geen benul hebben van wat ze aan het doen zijn, want anders waren ze ongetwijfeld in opstand gekomen.
Het zal in elk geval zaak worden om beter te letten op een storing zoals deze, zodat we eerder kunnen ingrijpen.






 van zolderkamer tot skybox ligt nu in de winkels")


